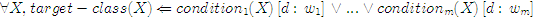- pp.10, Example 1.1, line 3: the sentence "For each relation, the attribute that represents the key or composite key component is underlined." should be removed
- pp.19, paragraph 2 from the bottom: the sentences "A heterogeneous database consists of a set of interconnected, autonomous component databases. The components communicate in order to exchange information and answer queries." should be added at the beginning of this paragraph
- pp.28, paragraph 2, line 5: "This is often sufficient to ensure the completeness of the algorithm." should be "For some mining tasks, such as association, this is often sufficient to ensure the completeness of the algorithm."
- pp.41, paragraph 2, line 8: "souces" should be "sources"
- pp.59, Figure 2.10: for slice, the [Vancouver, security] subcube, "440" should be "400"
- pp.67, paragraph 2, line 1: "client" should be "front-end client layer"
- pp.73, paragraph 4, line 6: "week <" should be removed
- pp.75, Example 2.12, line 4: "equisized" should be "equal-sized"
- pp.77, paragraph 2, line 6: "chunks 1 to four" should be "chunks 1 to 4"
- pp.78, paragraph 1, line 1: "10 x 4000" should be "40 x 1000"
- pp.78, Figure 2.16 (a): the line connecting "all" and "B" should be removed, while a line connecting "all" and "A" should be added
- pp.81, Figure 2.18: the line connecting "Main Street" and "T459" should be removed, while a line connecting "Main Street" and "T238" should be added
- pp.82, Example 2.15, line 1: "[time, item, location]" should be "[item, location, time]"
- pp.96, paragraph 3 from the bottom, line 4: "an graphical" should be "a graphic"
- pp.102, Exercise 2.13, line 4: "within 25% of the minimum shelf life, and within 50% of" should be "between 1.25 and 1.5 of"
- pp.127, paragraph 1, line 1: "weighted sum of the original values" should be "weighted sum of the variance of the original values"
- pp.134, equation 3.6
should be:
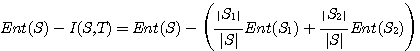
- pp.137, Figure 3.16, Step 2: "LOW ' = $1,000,000" should be "LOW ' = -$1,000,000"
- pp.139, paragraph 2, line 4: "an attribute defining a high" should be "an attribute defining a higher"
- pp.158, Figure 4.4: the pie chart is disproportional because the sum of class A's count and class B's count should be bigger than class C's count
- pp.162, line 1: "<attribute_or_dimemsion_list>" should be "<attribute_or_dimension_list>"
- pp.205, equation 5.8 should be:
- pp.231, paragraph 3: the first sentence should be "Apriori property. All nonempty subsets of a frequent itemset must also be frequent"
- pp.231, paragraph 3: a new paragraph should start from the second sentence, and "This property" should be "The Apriori property"
- pp.240, paragraph 1, line 4: ", I5: 1)" should be ", (I5: 1)"
- pp.240, paragraph 1, line 5: "I5 is linked to I2" should be "I5 is linked to I1"
- pp.241, Table 6.1, row I4: "{(I2 I1: 1), I2: 1)}" should be "{(I2 I1: 1), (I2: 1)}
- pp.241, Table 6.1, row I3: "I2 I3: 4, I1, I3: 2, I2, I1 I3: 2" should be "I2 I3: 4, I1, I3: 4, I2 I1 I3: 2"
- pp.241, paragraph 3, line 3: "I1 I3: 2" should be "I1 I3: 4"
- pp.242, Figure 6.10,
line 4 from the bottom: "
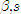 " should be "
" should be " 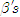 "
"
- pp.242, Figure 6.10, line 1 from the bottom: "F_growth" should be "FP_growth"
- pp.256, equation 6.15: "age(X, 34)" should be "age(X, "34")"
- pp.256, equation 6.16: "age(X, 35)" should be "age(X, "35")"
- pp.256, equation 6.17: "age(X, 34)" should be "age(X, "34")"
- pp.256, equation 6.18: "age(X, 35)" should be "age(X, "35")"
- pp.261, Table 6.4:
"
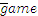 " should be "
" should be " 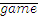 "
"
- pp.261, Table 6.4: "row"should be "row"
- pp.261, Table 6.4: "col" should be "col"
- pp.274, line 9: "{Asia, Europe, U.S.A., Latin_America}
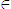 foreign." should be "{Asia, Europe, Latin_America}
foreign." should be "{Asia, Europe, Latin_America}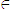 foreign. {Canada, U.S.A.}
foreign. {Canada, U.S.A.}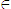 North_America."
North_America."
- pp.274, line 10: "2%" should be "20%"
- pp.274, line 13: "multilevel association rules" should be "multilevel (but not cross-level) association rules"
- pp.274, line 15: "multilevel association rules" should be "multilevel (but not cross-level) association rules"
- pp.274, line 16: "1%" should be "10%"
- pp.275, Exercise 6.15,
line 1 from the bottom: "variance(S)
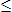 v" should be "avg(S)
v" should be "avg(S) 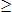 v"
v"
- pp.276, paragraph 1, line 2: "published independently by Agrawal and Srikant [AS94], and" should be "done by Agrawal and Srikant [AS94]. A variation of the algorithm using a similar pruning heuristic was developed independently by"
- pp.276, paragraph 1, line 5 from the bottom: "queries are described" should be "query computation was studied"
- pp.276, paragraph 1, line 4 from the bottom: "and Beyer" should be "and an efficient iceberg cube computation method was developed by Beyer"
- pp.303, line 1 from the bottom: "or as output units" should be "or as functional units"
- pp.304, Figure 7.8: "wkj" should be "wjk"
- pp.304, paragraph 1, line 1: "two layers of output" should be "two layers of functional"
- pp.304, paragraph 1, line 4: "an output unit" should be "a functional unit"
- pp.306, paragraph 1, line 4: "function is used" should be " function is often used"
- pp.311, paragraph 1: the last sentence should be "This consists of simplifying the network structure by removing weighted links that have the least effect on the trained network. For example, a weighted link may be deleted if such removal does not result in a decrease in the classification accuracy of the network."
- pp.324, paragraph 3 from the bottom, line 1: "boostrap" should be "bootstrap"
- pp.328, line 1 from the bottom: "salary" should be "status"
- pp.329, Exercise 7.6 (c) should be: "Given a data sample with the values "systems", "26 ... 30", and "46K ... 50K" for the attributes department, age, and salary, respectively, what would a naive Bayesian classification of the status for the sample be?"
- pp.331, paragraph 1, line 3: "Zytko" should be "Zytkow"
- pp.367, line 2 under equation 8.22: "determined the distance" should be "determined by the distance"
- pp.368, the paragraph "From the density function ... attractor for a 2-D data set" should be removed
- pp.368, paragraph 2 from the bottom, line 4: "sk" should be "xk"
- pp.403, equation 9.1: "l+" should be "L+"
- pp.407, Figure 9.2, row 1 of the time dimension table: "time" should be "hour"
- pp.407, Example 9.6, line 2: "region temperature" should be "region, temperature"
- pp.460, line 2: "handling large data sets" should be "in handling large data sets"
- pp.480, line 3 from the bottom: "and data mining process visualization" should be "data mining process visualization, and interactive visual data mining"
| Chapter 1 | Introduction |
| Erratum:
|
|
| [back] | |
| Chapter 2 | Data Warehouse and OLAP Technology for Data Mining |
| Erratum:
|
|
| [back] | |
| [go top] | |
| Chapter 3 | Data Preprocessing |
| Erratum:
|
|
| [back] | |
| [go top] | |
| Chapter 4 | Data Mining Primitives, Languages, and System Architectures |
| Erratum:
|
|
| [back] | |
| [go top] | |
| Chapter 5 | Concept Description: Characterization and Comparison |
| Erratum:
|
|
| [back] | |
| [go top] | |
| Chapter 6 | Mining Association Rules in Large Databases |
| Erratum:
|
|
| [back] | |
| [go top] | |
| Chapter 7 | Classification and Prediction |
| Erratum:
|
|
| [back] | |
| [go top] | |
| Chapter 8 | Cluster Analysis |
| Erratum:
|
|
| [back] | |
| [go top] | |
| Chapter 9 | Mining Complex Types of Data |
| Erratum:
|
|
| [go top] | |
| Chapter 10 | Applications and Trends in Data Mining |
| Erratum:
|
|
| [go top] | |