ACL 2026 Accepted Papers
ACL (Annual Meeting of the Association for Computational Linguistics) is one of the top international conferences in natural language processing and computational linguistics. Organized annually by the Association for Computational Linguistics, it brings together frontier research from universities, research institutes, and industry in language understanding, machine translation, information extraction, dialogue systems, large language models, multimodal language intelligence, and related areas. ACL is a CCF-A conference in artificial intelligence and, together with EMNLP and NAACL, forms the core group of the most influential conferences in NLP. According to Google Scholar Metrics 2025, ACL ranks No. 1 in the Computational Linguistics category.
The Large Model Center at the School of Computer Science, Nanjing University has 9 papers accepted by ACL 2026, including 5 ACL Main papers and 4 Findings of ACL papers.
01
ACL Track: ACL Main
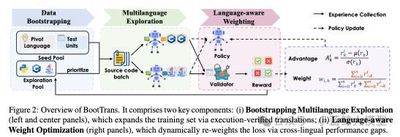
Title: Bootstrapping Code Translation with Weighted Multilanguage Exploration
Authors: Yuhan Wu, Huan Zhang, Wei Cheng, Chen Shen, Jingyue Yang, Wei Hu
Affiliations: Nanjing University
Link: https://arxiv.org/abs/2601.03512
Paper Summary:
BootTrans studies multilingual code translation and aims to reduce reliance on high-quality parallel corpora and executable test data. To address the scarcity of parallel verification data, the uneven difficulty of translation directions, and the tendency of models to favor easy translation paths, the authors propose BootTrans, a bootstrapped code translation framework that does not require parallel corpora. It uses the transferability of unit tests across programming languages to build a cyclic training mechanism driven by two data pools. During rollouts, the framework dynamically collects successful translation samples and further expands back-translation and cross-language translation paths, moving beyond traditional pivot-language constraints. BootTrans also introduces a language-aware dynamic weighted optimization strategy that adaptively adjusts training weights according to the difficulty of each translation direction, encouraging the model to focus on harder or lower-performing target languages. Experiments on HumanEval-X and TransCoder-Test show that BootTrans significantly outperforms base models and existing code-translation fine-tuning methods, achieving up to a 16.57% performance gain on Llama-3.1-8B. It also generalizes well to unseen languages, low-resource languages, and more complex class-level code translation tasks.
02
ACL Track: ACL Main
Title: AEA: Adaptive Expert Allocation Improves Sentence Embeddings from Mixture-of-Experts LLM
Authors: Shufan Yang, Zifeng Cheng, Zhiwei Jiang, Qingfeng Qi, Yafeng Yin, Cong Wang, Ao Zhou, Qing Gu
Affiliations: Nanjing University
Paper Summary:
Directly extracting sentence embeddings from Mixture-of-Experts (MoE) models is a promising but underexplored direction because it requires no additional data or fine-tuning. Previous studies have used semantic-compression prompts or expert routing information to improve sentence embeddings, but they usually assign a fixed number of experts uniformly across all layers and tokens, ignoring layer-wise and token-wise heterogeneity. This paper identifies two key phenomena in MoE models: layer-level differences in expert homogeneity, which indicate that different layers require different expert budgets, and imbalanced token contributions, which indicate that different tokens should also receive different numbers of experts. The authors propose Adaptive Expert Allocation (AEA), a framework that dynamically performs layer-level and token-level expert allocation to improve embedding quality. AEA assigns fewer experts to layers with higher expert homogeneity and to tokens with lower attention importance, where layer homogeneity is measured by the similarity among embeddings produced by experts in each layer. The method is plug-and-play, integrates smoothly with existing prompting methods, and introduces no additional time overhead. Experiments on STS tasks show that AEA consistently improves sentence embeddings across multiple MoE models.
03
ACL Track: ACL Main
Title: Focusing Condition: Inference-Time Self-Contrastive Steering Elicits Better Conditional Text Embeddings in LLMs
Authors: Zifeng Cheng, Lingyun Qian, Zhiwei Jiang, Cong Wang, Yafeng Yin, Fei Shen, Ao Zhou, Qing Gu
Affiliations: Nanjing University; National University of Singapore
Paper Summary:
Extracting conditional text embeddings directly from large language models has attracted broad interest because it requires no additional data or fine-tuning. Existing methods add conditions to prompts to guide LLMs toward condition-specific embeddings. However, relying only on prompts often fails to produce high-quality conditional embeddings, because these embeddings remain entangled with general-purpose text embeddings and therefore degrade in quality. This work proposes an inference-time self-contrastive steering (SCS) method that improves conditional embeddings by constructing unconditional general text embeddings and steering the conditional representation to focus more on the target condition. Specifically, the method masks out the condition by modifying the attention mask and positional encoding, obtains unconditional text embeddings, and intervenes in multi-head self-attention computation. The method is efficient and requires only one extra multi-head self-attention computation at inference time. Large-scale experiments on clustering, semantic textual similarity, and triplet-alignment datasets show that SCS can improve existing prompt-based methods across different LLMs in a training-free and plug-and-play manner.
04
ACL Track: ACL Main
Title: A Data-Efficient Path to Multilingual LLMs: Language Expansion via Post-training PARAM∆ Integration into Upcycled MoE
Authors: Hao Zhou, Tianhao Li, Zhijun Wang, Shuaijie She, Linjuan Wu, Hao-ran Wei, Baosong Yang, Jiajun Chen, Shujian Huang
Affiliations: Nanjing University; Tongyi Lab; Zhejiang University
Paper Summary:
Current large language models mainly possess strong English or Chinese abilities, while their capabilities in low-resource languages remain limited. Traditional language-expansion methods first use large-scale monolingual data in continued pretraining to add basic knowledge for target languages, and then perform post-training to align the model with human preferences. Because post-training requires large amounts of high-quality annotated data in the target language, many works attempt to replace post-training with parameter merging to bypass the data bottleneck. However, these methods face a key conflict: parameters obtained from continued pretraining (CPT) and those obtained from post-training can be incompatible. To address this issue, the authors propose DeltaMoE, which expands multiple experts and adds the post-training parameter delta to each expert, helping the MoE model acquire alignment ability. Experiments show that DeltaMoE brings significant improvements on expanded languages under both matched parameter counts and matched training FLOPs, while also preserving knowledge in original languages and avoiding catastrophic forgetting.
05
ACL Track: ACL Main
Title: Reasoning While Asking: Transforming Reasoning Large Language Models from Passive Solvers to Proactive Inquirers
Authors: Xin Chen, Feng Jiang, Yiqian Zhang, Hardy Chen, Shuo Yan, Wenya Xie, Min Yang, Shujian Huang
Affiliations: Nanjing University; Artificial Intelligence Research Institute, Shenzhen University of Advanced Technology; Shenzhen Institute of Advanced Technology, Chinese Academy of Sciences
Link: https://arxiv.org/abs/2601.22139
Paper Summary:
Reasoning large language models such as DeepSeek-R1 have achieved strong performance on complex tasks through explicit reasoning traces. However, these models are still constrained by a blind self-thinking paradigm: when user instructions have missing premises or ambiguous intent, the model often performs lengthy internal reasoning, leading to overthinking, hallucinations, and conclusions that deviate from the user’s true intent. This harms interaction efficiency and user experience. To address this issue, the authors propose Proactive Interactive Reasoning (PIR), a new paradigm that transforms reasoning LLMs from passive solvers into proactive inquirers. PIR enables models to interleave thinking, asking, and feedback during reasoning, so they can clarify key uncertainties and better align with user intent.
The PIR framework has two stages. The first is interaction capability activation, where uncertainty-aware data augmentation identifies key decision points with uncertainty during reasoning and injects clarification questions and simulated user replies at those points. This converts monotonic reasoning traces into an interactive think-ask-feedback format and uses supervised fine-tuning to activate proactive questioning ability. The second is user-intent alignment, where the authors build a user-simulator-based Group Relative Policy Optimization framework (US-GRPO). It combines extrinsic rewards for task correctness with intrinsic rewards for the helpfulness and efficiency of model questions, guiding the model to solve tasks accurately while reducing unnecessary interaction. Experiments on multi-turn interaction tasks in mathematical reasoning, code generation, and document editing show that PIR consistently improves over baselines and significantly reduces reasoning computation and redundant interactions. Evaluations on non-interactive benchmarks such as MMLU, MMLU-Pro, TriviaQA, SQuAD, and Missing Premise tests further show PIR’s generalization potential and robustness.
06
ACL Track: Findings of ACL
Title: Understanding New-Knowledge-Induced Factual Hallucinations in LLMs: Analysis and Interpretation
Authors: Renfei Dang, Peng Hu, Zhejian Lai, Changjiang Gao, Min Zhang, Shujian Huang
Affiliations: Nanjing University; Huawei Translation Services Center
Link: https://arxiv.org/abs/2511.02626
Paper Summary:
Previous studies have shown that fine-tuning large language models on new knowledge can induce factual hallucinations, causing models to answer incorrectly when asked about information they originally knew. However, the forms and mechanisms of these hallucinations remain insufficiently understood. To fill this gap, the authors construct a controlled dataset, Biography-Reasoning, and conduct fine-grained analyses across multiple knowledge types and knowledge-based question answering and reasoning tasks.
They find that factual hallucinations seriously affect not only tasks involving the newly learned knowledge, but also other evaluation tasks. When a specific knowledge type in fine-tuning data consists entirely of new knowledge, LLMs show a stronger tendency toward hallucination. Through interpretability analysis, the authors further find that learning new knowledge weakens the model’s attention to key entities in the input question and makes it rely more heavily on surrounding context, thereby increasing hallucination risk. Conversely, reintroducing a small amount of known knowledge in the later training stage can restore attention to key entities and significantly reduce hallucinations. The paper also shows that this disturbed attention pattern can propagate between lexically similar contexts, causing hallucinations to spread beyond the original task.
07
ACL Track: Findings of ACL
Title: PEGRL: Improving Machine Translation by Post-Editing Guided Reinforcement Learning
Authors: Yunzhi Shen, Hao Zhou, Xin Huang, Xue Han, Junlan Feng, Shujian Huang
Affiliations: Nanjing University; China Mobile
Link: https://arxiv.org/abs/2511.02626
Paper Summary:
Reinforcement learning has shown strong potential for LLM-based machine translation, and recent methods such as GRPO have achieved notable performance gains. However, applying reinforcement learning effectively to translation still faces several challenges. Policy-gradient estimates based on Monte Carlo baselines have high variance, and the large trajectory space encourages global exploration while making fine-grained local optimization harder.
To address these challenges, the authors propose PEGRL, a two-stage reinforcement learning framework that introduces post-editing as an auxiliary task to stabilize training and guide optimization. At each step, the model first samples translation outputs and then constructs post-editing task inputs from them. Low-variance gradients from the post-editing task can then propagate during training, strengthening local optimization while preserving global exploration.
The authors also design a task-specific weighting mechanism to amplify the influence of post-editing gradients, producing a moderately biased but more sample-efficient gradient estimator. Extensive experiments on English-to-Finnish, English-to-Turkish, and bidirectional English-Chinese translation show that PEGRL consistently improves over multiple reinforcement learning baselines. On English-to-Turkish, its COMETKiwi score is comparable to advanced LLM translation systems such as DeepSeek-V3.2.
08
ACL Track: Findings of ACL
Title: To Diff or Not to Diff? Structure-Aware and Adaptive Output Formats for Efficient LLM-based Code Editing
Authors: Wei Cheng, Yongchang Cao, Chen Shen, Binhua Li, Jue Chen, Yongbin Li, Wei Hu
Affiliations: Nanjing University; Tongyi Lab
Paper Summary:
This paper addresses the high latency and inference cost of LLM-based code editing in interactive coding assistants. Mainstream approaches often use full-code generation, which regenerates the entire file even when only a few lines need to change, causing substantial token waste and response latency. Traditional diff formats can shorten generation length, but because they rely on line numbers or fragmented content snippets, they can break code structure and make model outputs less natural, reducing editing accuracy. To solve this problem, researchers from Nanjing University and Tongyi Lab propose a structure-aware diff format and the AdaEdit adaptive editing strategy. The structure-aware diff organizes code changes into syntactically complete logical units based on the abstract syntax tree, preserving the efficiency of diff while improving the naturalness of model generation. AdaEdit further enables the model to decide whether to use diff generation or full generation for each editing task, selecting the more token-efficient output format. Experiments on Qwen2.5-Coder, DeepSeek-Coder, and multiple Python and JavaScript datasets show that the method matches or surpasses full-generation baselines in editing accuracy, reduces generation latency and token cost by more than 30% on long-code editing tasks, and achieves output-format selection accuracy above 90%. The study shows that optimizing output format and generation strategy can significantly improve the practical efficiency of coding assistants without increasing model size.
09
ACL Track: Findings of ACL
Title: How Do Answer Tokens Read Reasoning Traces? Self-Reading Patterns in Thinking LLMs for Quantitative Reasoning
Authors: Haoyang Chen, Yi Liu, Jianzhi Shao, Tao Zhang, Chengfu Huo, Wei Hu
Affiliations: Nanjing University
Paper Summary:
This paper studies how reasoning LLMs that first think and then answer use their preceding reasoning traces during answer generation. It reveals a stable benign self-reading pattern in thinking models for quantitative reasoning. When a model answers correctly, attention during the answer stage usually moves progressively along the reasoning chain and remains focused on key semantic anchors such as problem constraints, solution plans, reflection and verification steps, and final conclusions. Incorrect samples more often show scattered attention and disordered reading trajectories. Based on this finding, the Nanjing University large model research group proposes a training-free activation steering method driven by Self-Reading Quality (SRQ). SRQ measures whether the model reads along an effective reasoning path from a geometric perspective and whether it focuses on key reasoning evidence from a semantic perspective. The method then constructs activation steering vectors from high- and low-SRQ samples to guide the model toward a more orderly, focused, and stable internal state. Experiments on GSM8K, MATH500, SciQ, AIME24-25, and other quantitative reasoning benchmarks show consistent improvements across reasoning models including R1-Distill-Qwen-7B, R1-Distill-Llama-8B, and Qwen3-4B-Thinking. The approach is also compatible with mainstream activation steering mechanisms such as CAA, Conceptor, and PCA-CAA. This study deepens the understanding of how reasoning models read their reasoning traces during answer generation and provides a general and effective internal supervision signal for improving reasoning without additional training.