ISCA 2026 | 新型MoE LLM端侧推理加速方法,解码延迟缩短48%
00 概述
近日,南京大学戴海鹏老师团队在边缘端大语言模型推理加速方向取得重要突破,通过设计一套全新的算法-系统协同设计的专家替换(Expert Substitution)机制,解决了在显存受限的边缘硬件上部署混合专家(MoE)模型时由动态卸载带来的高延迟挑战。论文“SMoE: An Algorithm-System Co-Design for Pushing MoE to the Edge via Expert Substitution”被第53届计算机体系结构国际研讨会(53rd Annual International Symposium on Computer Architecture, ISCA)成功录用。这是南大团队主导发表的第一篇ISCA论文。
ISCA是中国计算机学会推荐的A类会议,也是计算机体系结构领域历史最悠久、最权威的会议,自1973年首次举办以来,已有超过50年的历史。该会议由 ACM SIGARCH(ACM计算机体系结构特别兴趣组)和 IEEE TCCA(IEEE 计算机体系结构技术委员会)联合赞助举办。
01 研究动机
近年来,随着大语言模型在边缘设备中的广泛部署,MoE架构成为了一种极具潜力的低开销推理途径。然而,由于边缘设备的GPU显存有限,无法同时容纳所有专家,系统在推理时不得不将部分专家频繁卸载到较慢的CPU内存中。由于PCIe传输和CPU计算比GPU执行慢10到100倍,这种数据迁移引入了极高的推理延迟。通过对细粒度MoE模型的深入分析,研究团队发现了现有卸载策略的盲区:它们忽视了被激活专家在重要性上的显著差异。在实际推理中,尽管每次会激活Top-k个专家,但通常只有少数专家能获得高门控分数(高分活跃专家),而其余专家的得分极低,甚至与未激活专家相似(低分活跃专家)。
这一观察揭示了当前MoE在线卸载机制设计中的根本性问题:系统耗费了大量时间进行CPU计算和PCIe传输,却仅仅为了处理那些对最终输出影响极小的低分专家。因此,如何在不损害模型精度的前提下,设计一种对GPU友好的专家调度机制以大幅降低推理延迟,成为了亟待解决的核心挑战。
02 解决方案
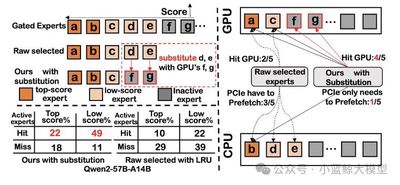
图1: SMoE核心理念与专家替换调度机制示意图
论文从算法-系统协同设计的层面提出了创新的解决方案 SMoE,通过低分专家替换、高分专家预取和CPU辅助任务负载调度三个协同设计的核心机制来应对上述挑战。系统的核心理念是打破将卸载纯粹视为调度问题的传统思维,利用专家的重要性来指导决策,将低重要性的活跃专家直接替换为GPU显存中已缓存且功能相似的闲置专家,从而在保持精度的同时大幅减少显存使用、数据传输和PCIe开销。
在低分专家替换方面,系统设计了专家缓存路由器(expert-cache router)以及基于历史分数的缓存驱逐策略,精准识别低分专家并用显存内的同等分数闲置专家进行替换,最大化GPU专家的缓存命中率。在高分专家预取方面,系统仅针对预测出的高分专家进行针对性加载,这不仅大幅降低了PCIe的带宽压力,还确保了数据加载与计算时间的有效重叠。在CPU辅助计算方面,系统引入了动态的两指针调度算法来平衡CPU计算与PCIe传输时间,有效处理那些既无法被替换又未能成功预取的专家,防止流水线停滞。
03 实验效果

图2: SMoE与不同方法在各类工作负载下的TPOT对比。
在低批处理量(low-batch)的真实边缘推理环境中进行的评估显示,SMoE在解码延迟(TPOT)和模型精度两个关键指标上均取得了卓越表现。在解码延迟方面,相比于现有的最先进方法,SMoE在batch=1 时平均减少了24%的延迟,而在batch=3 时则进一步将平均延迟降低了35%。特别是在A6000硬件配置下的测试中,SMoE 实现了高达48%的解码延迟缩减,并将专家GPU缓存命中率维持在60%以上。
在模型精度方面,通过在 Gaokao、MMLU、HumanEval 等多个领域数据集的广泛测试表明,只要将专家替换阈值控制在合理范围内(如低于0.35),SMoE 带来的精度损失几乎可以忽略不计。
SMoE 在技术上探索了从单纯的“调度优化”向“基于分数的专家替换”这一全新路径的转变。该工作是团队在MLSys领域的最新研究成果,为显存受限的边缘设备实现大模型的高效无损部署提供了一种极具潜力的解决思路。