ICLR 2026录用论文简介
ICLR(International Conference on Learning Representations)是人工智能领域中专注于深度学习和表征学习的顶级学术会议之一。南京大学计算机学院大模型中心有11篇论文被ICLR 2026录用。
01
题目:Long-Context Attention Benchmark: From Kernel Efficiency to Distributed Context Parallelism
作者:Tao Bu (卜韬), Qiangang Wang (王乾钢), Bowen Zeng (曾博文), Hanwen Sun (孙瀚文), Yunpeng Huang (黄云鹏), Chun Cao (曹春), Jingwei Xu (徐经纬)
单位:南京大学;北京大学;浙江大学
链接:https://arxiv.org/abs/2510.17896
论文简介:
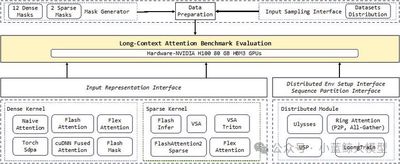
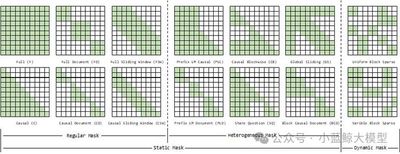
基于 Transformer 的大语言模型虽然取得了显著成功,但其基于 softmax 的注意力机制在序列长度增长时会带来二次方级的计算与内存开销,成为长上下文训练的主要瓶颈。现有工作主要从两方面优化:一是算子层面的优化(加速稠密或稀疏注意力计算),二是模块层面的分布式注意力或上下文并行策略(在多设备间扩展计算)。然而,目前缺乏系统性的评测框架,既存在算子对比不全面的问题,也存在不同上下文并行方法之间性能分析不清晰的问题。为此,本文提出了一个统一的基准测试框架,整合多种注意力算子和上下文并行机制,并从注意力掩码模式以及序列长度与分布式规模两个关键维度进行评估。在最多96张GPU的实验中,该基准实现了可复现的对比分析,揭示了不同方法之间的权衡关系,并为长上下文大模型训练中的注意力机制设计与部署提供了实践指导。
02
题目:PoseX: A Large-Scale Cross-Docking Benchmark for Real-World Protein-Ligand Docking
作者:Yize Jiang (蒋一泽), Xinze Li (李欣泽), Yuanyuan Zhang (张媛媛), Jin Han (韩进), Youjun Xu (徐优俊), Ayush Pandit, Zaixi Zhang (张载熙), Mengdi Wang (王梦迪), Mengyang Wang (王孟洋), Chong Liu (刘翀), Guang Yang (杨光), Yejin Choi, Wu-Jun Li (李武军), Tianfan Fu (符天凡), Fang Wu (吴方), Junhong Liu (柳俊宏)
单位:微元合成;普林斯顿大学;南京大学;字节跳动;斯坦福大学;北京大学
链接:https://arxiv.org/abs/2505.01700
论文简介:
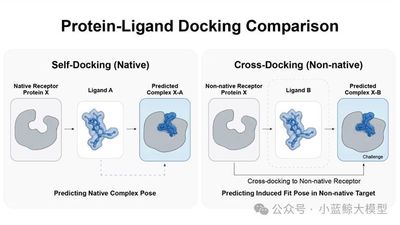
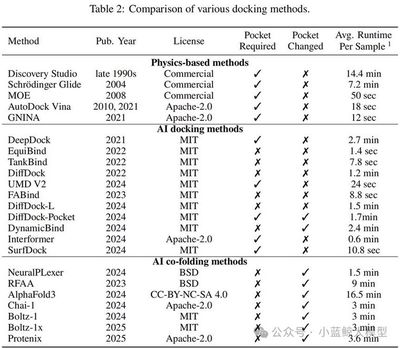
分子对接是生物医药研发与工业酶工程的核心技术,传统方法难以适配蛋白质动态构象变化,跨构象对接(Cross-Docking)成为行业公认难题。长期以来,领域内缺乏统一、高质量的实战化评测基准,导致多数算法在实验室场景表现优异,却无法落地真实研发场景。为此,本工作推出 PoseX 开放式协作评测平台,构建全球首个大规模 Cross-Docking 专项基准,包含 718 个样本的自对接数据集与 1312 个样本的跨构象对接数据集,覆盖物理方法、AI 对接、AI 共折叠三大流派共 24 种主流算法。严苛评测证实:顶尖 AI 算法在跨构象对接任务中全面超越传统物理方法,其中 SurfDock 实现 SOTA 性能,经 Relaxation 后处理后成功率突破 77%;同时明确盲对接与指定口袋对接的性能差异、AI 模型泛化能力规律。PoseX 填补行业实战评测空白,为合成生物学、新药研发、酶工程提供数字化底层支撑,加速分子与蛋白结合的按需设计落地。
03
题目:PIXNERD: PIXEL NEURAL FIELD DIFFUSION
作者:Shuai Wang, Ziteng Gao, Chenhui Zhu, Weilin Huang, Limin Wang
单位:Nanjing University, ByteDance Seed, National University of Singapore
链接:https://arxiv.org/pdf/2507.23268
论文简介:
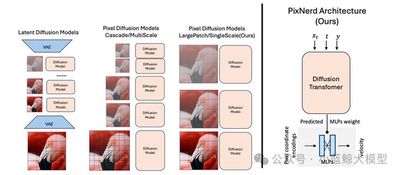
当前扩散变换器的优异性能,依赖于预训练变分自动编码器(VAE)构建的压缩隐空间。然而,这种两阶段训练范式不可避免地会产生误差累积与解码伪影问题。为解决上述缺陷,研究人员转而探索像素空间建模方案,但该方案往往需要搭建复杂级联流程,同时会大幅增加序列词元的计算复杂度。受隐空间下简洁高效的扩散变换器架构启发,本文提出基于大块补丁的扩散变换器实现像素空间扩散建模,并结合神经场对大块补丁进行解码,构建了轻量化、单阶段的端到端解决方案。我们将该方法命名为像素神经场扩散变换器(PixNerd)。依托 PixNerd 高效的神经场表征能力,在无需复杂级联结构与 VAE 的前提下,该模型在 256×256 分辨率 ImageNet 数据集上取得 1.93 的 FID 分数;相较于现有像素级扩散模型,推理延迟降低近 8 倍。本文进一步将 PixNerd 框架拓展至文生图任务,在 GenEval 基准测试中取得 0.73 的综合得分,在 DPG 基准测试中综合得分达 80.9,具备极强的算法竞争力。
04
题目:RIVER: A Real-Time Interaction Benchmark for Video LLMs
作者:Yansong Shi, Qingsong Zhao, Tianxiang Jiang, Xiangyu Zeng, Yi Wang, Limin Wang
单位:中国科学技术大学,上海人工智能实验室、复旦大学、南京大学
论文简介:
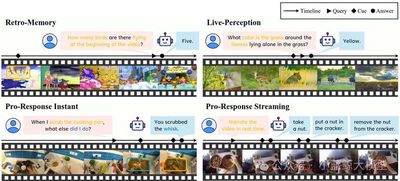
视频大型语言模型(Video LLMs)已展现出令人瞩目的能力,但绝大多数仍基于离线模式运行,严重制约了其实时交互的潜力。为填补这一空白,我们推出视频大语言模型实时交互基准(RIVER Bench),旨在通过流式多媒体信息输入来评估模型与人类的实时交互能力。RIVER Bench创新性地构建了包含回溯记忆、实时感知与主动响应三大任务的评估框架,摒弃了传统“一次性理解全视频”的离线范式,转而模拟人类互动对话的形式。我们整合了多源异构、时长各异的视频数据,并进行精细化标注,以构造实时交互的形式。评测结果显示,尽管离线模型在单次问答任务中表现优异,却在实时处理场景中捉襟见肘。针对现有模型在在线交互范式下暴露的长期记忆薄弱、未来感知不足等局限,我们提出了一种通用改进方案,显著提升了模型在实时交互中的灵活性与适应性。我们期望这项工作能推动实时交互式视频理解模型的发展,并为该领域的未来研究提供新的思路与方向。
05
题目:ARBITRARY GENERATIVE VIDEO INTERPOLATION
作者:Guozhen Zhang (张国珍), Haiguang Wang (王海光), Chunyu Wang (王春雨), Yuan Zhou (周源), Qinglin Lu (陆青林), Limin Wang (王利民)
单位:南京大学,腾讯混元,上海人工智能实验室
论文简介:
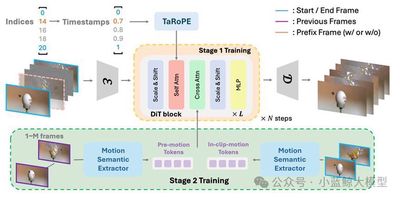
生成式视频插帧(VFI)可基于给定的起止帧对合成中间帧,在视频创作中发挥着核心作用。然而,现有生成式 VFI 方法受限于仅能生成固定数量的中间帧,极大限制了视频创作过程中调整帧率或视频时长的灵活性。本文提出 ArbInterp,一种全新的生成式 VFI 框架,可实现任意时间戳、任意长度的高效插帧。具体而言,为支持任意时间戳插帧,我们提出了时间戳感知旋转位置编码(TaRoPE),该方法对时域旋转位置编码中的位置信息进行调制,使生成帧与目标归一化时间戳对齐。这一设计实现了对帧时间戳的细粒度控制,解决了现有工作中固定位置范式灵活性不足的问题。针对任意长度插帧,我们将长序列生成拆解为分段式帧合成,进一步设计了一种全新的外观-运动解耦条件策略:利用前序分段的起止帧保证外观一致性,借助时域语义维持运动连贯性,确保各分段间实现无缝的时空过渡。实验部分,我们构建了多尺度帧插帧(2 倍至 32 倍)的综合基准,以评估模型在任意插帧倍率下的泛化能力。结果表明,ArbInterp 在所有场景下均优于现有方法,具备更高的生成保真度与更流畅的时空连续性。
06
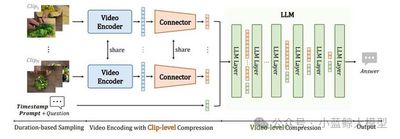
题目:VideoChat-Flash: Hierarchical Compression for Long-Context Video Modeling
作者:Xinhao Li(李新浩), Yi Wang(王毅), Jiashuo Yu(于家硕), Xiangyu Zeng(曾祥宇), Yuhan Zhu(朱宇涵), Haian Huang(黄海安), Jianfei Gao(高剑飞), Kunchang Li(黎昆昌), Yinan He(何毅楠), Chenting Wang(王晨汀), Yu Qiao(乔宇), Yali Wang(王亚立), Limin Wang(王利民)
单位:上海人工智能实验室,南京大学,中国科学院深圳先进技术研究院
论文简介:
长上下文视频建模对多模态大语言模型(MLLMs)至关重要,它使模型具备处理电影、在线视频流等内容的能力。尽管该领域已取得诸多进展,但由于极长视频上下文的高效理解存在固有难点,长视频处理仍面临巨大挑战。本文从模型架构、训练数据、训练策略与评估基准四个维度,针对这一问题提出系统性解决方案。首先,我们提出了一种全新的分层视频 Token 压缩方法(Hierarchical video token Compression, HiCo)。该方法利用长视频中的视觉冗余特性,从片段级到视频级对长视频上下文进行分层压缩,在保留核心关键细节的同时大幅降低计算量,实现了约 1/50 的极致压缩比,且几乎无性能损失。其次,我们提出了多阶段由短到长的学习范式,构建了名为 LongVid 的大规模真实世界长视频数据集,同时设计了一项高难度的多跳视频大海捞针(Multi-Hop Needle-In-A-Video-Haystack)基准测试。最终,我们构建了一款性能强大的视频多模态大语言模型 VideoChat-Flash。在 2B 与 7B 参数量级下,该模型在主流的长、短视频基准测试中均取得了领先性能;在开源模型范畴内,其首次在 10000 帧视频的大海捞针(NIAH)测试中实现了 99.1% 的准确率。
07
题目:CaReBench: A Fine-Grained Benchmark for Video Captioning and Retrieval
作者:Yifan Xu(许一凡),Xinhao Li(李新浩),Yichun Yang(杨旖纯),Desen Meng(孟德森),Rui Huang(黄锐),Limin Wang(王利民)
单位:南京大学,上海人工智能实验室
论文简介:
视频理解中的视频描述与视频检索任务,至今仍然是视频语言模型面临的重要挑战。现有的视频检索与视频描述基准大多仅包含较短的文本描述,因此难以充分评估模型对视频细节内容的深入理解能力。针对这一问题,本文提出了 CaReBench,一个面向细粒度视频描述与视频检索的测试基准。该基准包含 1000 对高质量视频及其人工标注的详细描述,并且为每个视频进一步提供了人工拆分的空间标注与时间标注。基于这一设计,作者提出了分别适用于视频检索与视频描述任务的两项评测指标 ReBias 和 CapST,从而能够更加系统地分析视频语言模型在空间信息理解与时间信息理解上的偏置问题。除此之外,本文还基于多模态大语言模型构建了一个统一基线,通过两阶段监督微调,同时支持细粒度视频检索和详细视频描述生成。实验结果表明,相比面向检索任务设计的 CLIP 类模型以及擅长视频描述的主流多模态大语言模型,该基线在细粒度视频检索和详细视频描述任务上都展现出了具有竞争力的性能,说明多模态大语言模型在统一建模这两类任务方面具有较大的潜力。

08
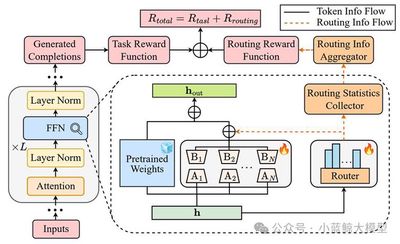
题目:Balancing the Experts: Unlocking LoRA-MoE for GRPO via Mechanism-Aware Rewards
作者:Changlian Ma (马畅联), Zizheng Huang (黄子政), Xiangyu Zeng (曾祥宇), Yi Wang (王毅), Cheng Liang (梁骋), Kun Tian (田鲲), Xinhai Zhao (赵昕海), Limin Wang (王利民)
单位:南京大学,上海人工智能实验室,华为诺亚实验室,上海创智学院,上海交通大学
论文简介:
参数高效的混合专家(MoE)架构(如LoRA-MoE)在微调中表现出色,但当应用到GRPO等先进强化学习算法训练时,常面临严重的路由崩溃和参数利用率不足的问题。为了应对这一挑战,我们提出了RO-GRPO,这是一种全新的机制感知强化微调框架。RO-GRPO的核心在于将训练期间收集的内部专家路由统计信息,如路由熵和负载分布转化为直接的标量奖励信号。我们将路由监督无缝集成到强化微调过程中,无需引入额外的训练阶段或可微辅助损失。实验结果表明,RO-GRPO在单模态和多模态数学推理基准测试中均显著提升了任务性能和专家参数的负载均衡,并有效缓解了文本退化现象。我们的工作证明了在GRPO中,可以通过设计标量奖励来显式引导模型内部机制的优化,从而将大模型的对齐范畴从单纯的外部行为微调扩展到了整体的内部机制对齐。
09
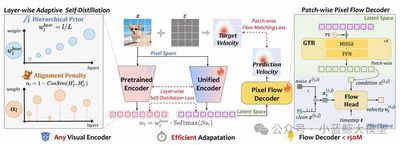
题目:UniFlow: A Unified Pixel Flow Tokenizer for Visual Understanding and Generation
作者:Zhenrong Yue, Haiyu Zhang, Xiangyu Zeng, Boyu Chen, Chenting Wang, Shaobin Zhuang, Lu Dong, Yi Wang, Limin Wang, Yali Wang
单位:上海交通大学,上海人工智能实验室,北京航空航天大学,中国科学院深圳先进技术研究院,南京大学,中国科学技术大学,中国科学院大学
论文简介:
分词器(Tokenizer)是视觉理解与生成任务的关键组件。为了迈向通用建模的终极目标,近期研究重点转向开发统一分词器。然而,现有的分词器在理解与生成之间面临着显著的性能权衡,这源于高层语义抽象与底层像素重建之间的内在冲突。为了应对这一挑战,我们提出了一种通用且统一的分词器,即 UniFlow,通过简洁的重建解码器灵活地适配任何视觉编码器。具体而言,我们对预训练良好的视觉编码器引入了层级自适应自蒸馏(Layer-wise Adaptive Self-Distillation),使 UniFlow 能够同时继承强大的视觉理解语义特征,并灵活地适配视觉生成的细粒度细节建模。此外,我们提出了一种轻量级的分块像素流解码器(Patch-wise Pixel Flow Decoder),通过建模从噪声状态回到分块像素域的条件流,高效地实现了高保真像素重建。通过利用语义特征作为解码器的视觉条件,我们有效地缓解了理解与生成之间的训练冲突。此外,分块学习策略简化了数据分布,从而提高了训练效率。在涵盖 7 个广泛研究的视觉理解与生成任务的 13 个挑战性基准测试上进行的广泛实验表明,UniFlow 实现了“双赢”的结果。例如,我们的 7B UniFlow-XL 不仅在平均理解基准上超越了 14B 的 TokenFlow-XL 约 6.05%,而且在视觉重建和生成方面也取得了具有竞争力的结果,分别在 rFID 和 gFID(无引导)上超越了 UniTok 0.15 和 0.09。
10
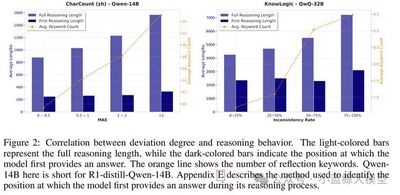
题目:The First Impression Problem: Internal Bias Triggers Overthinking in Reasoning Models
作者:Renfei Dang(党任飞), Zhening Li(李哲凝), Shujian Huang(黄书剑), Jiajun Chen(陈家骏)
单位:南京大学
链接:https://iclr.cc/virtual/2026/poster/10011746
论文简介:
推理模型常表现出“过度思考”(overthinking)现象。本文指出,由输入问题所激发的内部偏见(internal bias)是引发该行为的关键诱因。当模型遇到用户提出的问题时,会在推理之前立即对答案形成初步猜测;由于该猜测通常未被显式输出,且产生于系统性推理之前,我们将其定义为“内部偏见”。当该初步猜测与后续的推理过程或者推理结果不一致时,模型倾向于陷入过度反思。我们在多款模型与多种推理任务中验证了内部偏见与过度思考之间的显著关联。为更严谨地论证因果关系,我们设计了两种反事实干预实验:结果表明,在模型形成初步倾向后移除输入问题,能够显著减少对问题的内部偏见的影响,从而减少冗余推理;同时,人工注入偏见也会相应地改变模型的过度思考程度。进一步的可解释性实验表明,模型对输入问题的过度关注是内部偏见影响后续推理轨迹的关键作用机制。模型可能在关键步骤重新过分关注问题部分从而激活其对问题的内在偏见。最后,我们评估了多种旨在缓解过度思考的现有方法,但结果表明,在所有测试条件下,内部偏见的影响依然持续存在。


11
题目:DuPO: Enabling Reliable LLM Self-Verification via Dual Preference Optimization
作者:Shuaijie She(佘帅杰), Yu Bao(鲍宇), Yu Lu(卢宇), Lu Xu(许璐), Tao Li(李涛), Wenhao Zhu(朱文昊), Jianbing Zhang(张建兵), Shujian Huang(黄书剑), Shanbo Cheng(程善伯), Lu Lu, Yuxuan Wang(王雨轩)
单位:南京大学, 字节跳动Seed
链接:https://iclr.cc/virtual/2026/poster/10009423
论文简介:
现有大语言模型的训练仍面临关键瓶颈:基于人类反馈的强化学习(RLHF)依赖成本极高的人工标注,而基于可验证奖励的强化学习(RLVR)虽降低了标注负担,但其适用范围局限于可验证任务(如数学、代码)。传统的对偶学习通过任务对偶性提供自监督反馈,然而其严格的双向可逆性要求使其仅适用于少量对称任务,同时还受到模型在正向与逆向任务上能力不对称问题的制约。为此,本文提出 DuPO,一种基于通用对偶性的偏好优化框架。其核心思想是将原始任务的输入分解为已知部分与未知部分,将对偶任务重新定义为利用正向输出与已知信息重构未知部分,并有效缓解能力不对称问题。实验结果表明,DuPO 无需外部标注即可在多项任务上取得显著提升:在 756 个翻译方向的多语翻译任务上,COMET 平均提升 2.1 分;在四个高难度数学推理基准上,准确率平均提升 6.4 个百分点;DuPO无需训练即可在推理阶段通过重排序,无需额外微调带来 9.3 个百分点的性能增益。这些结果表明,DuPO 为大语言模型优化提供了一种可扩展、通用且无需标注的新范式,为更广泛开放领域的大模型自进化开辟了新方向。