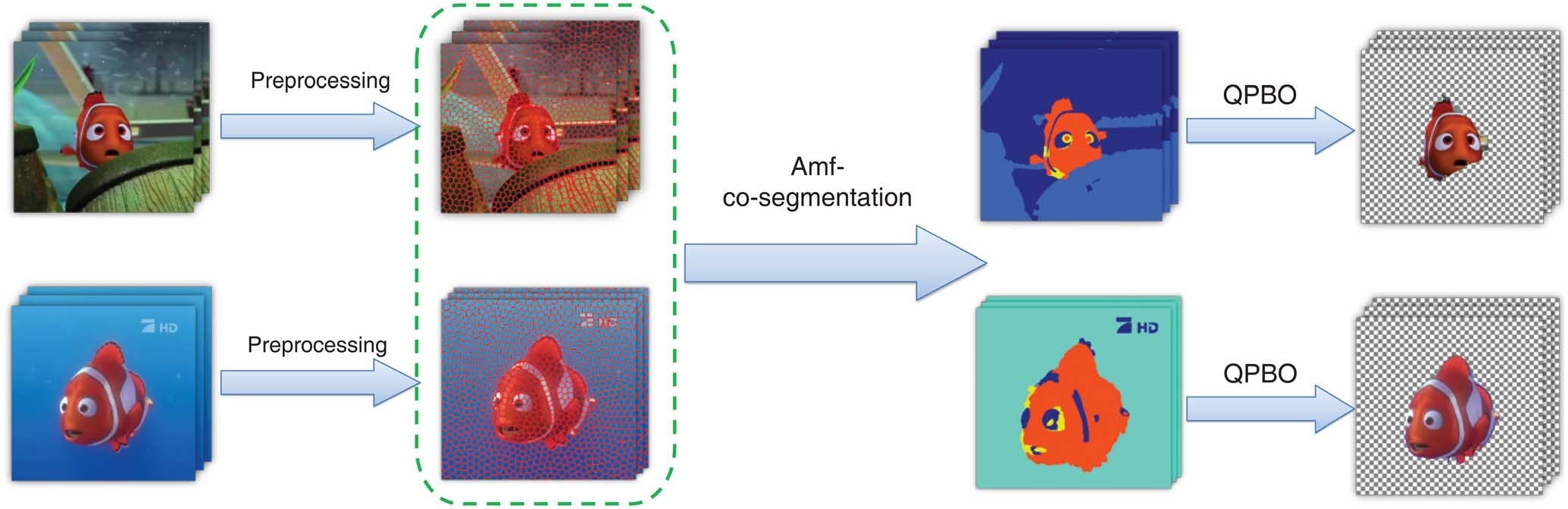
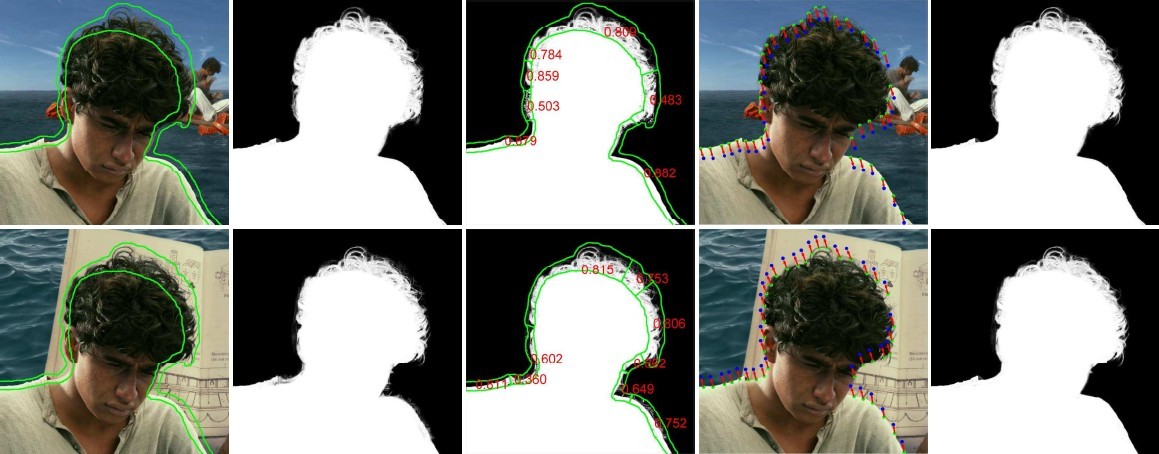
Video Object Co-Segmentation via Subspace Clustering and Quadratic Pseudo-Boolean Optimization in an MRF Framework
[Demo Page]
[Dataset coming soon, Contact us for the data now!]
[Bibtex]
Chuan Wang, Yanwen Guo, Jie Zhu, Linbo Wang, and Wenping Wang
In EEE Transactions on Multimedia, 2014, Volume:16, Issue:4, 903 - 916.
In this paper, we present a novel approach for automatically creating the photo collage that assembles the interest regions of a given group of images naturally. Previous methods on photo collage are generally built upon a well-defined optimization framework which computes all the geometric parameters and layer indexes for input photos on the given canvas by optimizing a unified objective function. The complex non-linear form of optimization function limits their scalability and efficiency. From the geometric point of view, we recast the generation of collage as a region partition problem such that each image is displayed in its corresponding region partitioned
from the canvas. The core of this is an efficient power diagram based circle packing algorithm, which arranges a series of circles assigned to input photos compactly in the given canvas. To favor important photos, the circles are associated with image importances determined by an image ranking process. A heuristic search process is developed to ensure that salient information of each photo is displayed in the polygonal area resulting from circle packing. With our new formulation, each factor influencing the state of a photo is optimized in an independent stage, and computation of the optimal states for neighboring photos are completely decoupled. This improves the scalability of collage results and ensures their diversity.We also devise a saliency-based image fusion scheme to generate seamless compositive collage. Our approach can generate the collages on non-rectangular canvases and supports interactive collage that allows the user to refine collage results according to his/her personal preferences. We conduct extensive experiments and show the superiority of our algorithm by comparing against previous methods.
|
Content-aware Photo Collage Using Circle Packing
[pdf]
[Demo Page]
[Link]
Zongqiao Yu, Lin Lu, Yanwen Guo, Rongfei Fan, Mingming Liu, Wenping Wang
In IEEE Transactions on Visualization and Computer Graphics, 2014, 20(2): 182-195.
In this paper, we present a novel approach for automatically creating the photo collage that assembles the interest regions of a given group of images naturally. Previous methods on photo collage are generally built upon a well-defined optimization framework which computes all the geometric parameters and layer indexes for input photos on the given canvas by optimizing a unified objective function. The complex non-linear form of optimization function limits their scalability and efficiency. From the geometric point of view, we recast the generation of collage as a region partition problem such that each image is displayed in its corresponding region partitioned
from the canvas. The core of this is an efficient power diagram based circle packing algorithm, which arranges a series of circles assigned to input photos compactly in the given canvas. To favor important photos, the circles are associated with image importances determined by an image ranking process. A heuristic search process is developed to ensure that salient information of each photo is displayed in the polygonal area resulting from circle packing. With our new formulation, each factor influencing the state of a photo is optimized in an independent stage, and computation of the optimal states for neighboring photos are completely decoupled. This improves the scalability of collage results and ensures their diversity.We also devise a saliency-based image fusion scheme to generate seamless compositive collage. Our approach can generate the collages on non-rectangular canvases and supports interactive collage that allows the user to refine collage results according to his/her personal preferences. We conduct extensive experiments and show the superiority of our algorithm by comparing against previous methods.
|
Object Tracking Using Learned Feature Manifolds
[Demo Page]
Yanwen Guo, Ye Chen, Feng Tang, Ang Li, Weitao Luo, and Mingming Liu
Computer Vision and Image Understanding, 2014, 118:128-139, DOI: 10.1016/j.cviu.2013.09.007. (SCI, EI)
Local feature based object tracking approaches have been promising in solving the tracking problems such as occlusions and illumination variations. However, existing approaches typically model feature variations using prototypes, and this discrete representation cannot capture the gradual changing property of local appearance. In this paper, we propose to model each local feature as a feature manifold to characterize the smooth changing behavior of the feature descriptor. The manifold is constructed from a series of transformed images simulating possible variations of the feature being tracked. We propose to build a collection of linear subspaces which approximate the original manifold as a low dimensional representation. This representation is used for object tracking. Object location is located by a feature-to-manifold matching process. Our tracking method can update the manifold status, add new feature manifolds and remove expiring ones adaptively according to object appearance. We show both qualitatively and quantitatively this representation significantly improves the tracking performance under occlusions and appearance variations using standard tracking dataset.
|
Confidence-Driven Image Co-matting
Linbo Wang, Tianchen Xia, Yanwen Guo, Ligang Liu, and Jue Wang
Computers & Graphics, 2014, 38(2): 131-139 (Proc. CAD/Graphics 2013, Best Paper Honorable Mention). (SCI, EI)
Single image matting, the task of estimating accurate foreground opacity from a given image, is a severely ill-posed
and challenging problem. Inspired by recent advances in image co-segmentation, in this paper, we present a novel
framework for a new task called co-matting, which aims to simultaneously extract alpha mattes in multiple images
that contain slightly-deformed instances of the same foreground object against diferent backgrounds. Our system
first generates trimaps for input images using co-segmentation, and an initial alpha matte for each image using single
image matting. Each alpha matte is then locally evaluated using a novel matting confidence metric learned from a
training data set. In the co-matting step, we first align the foreground object instances using appearance and geometric
features, then apply a global optimization on all input images to jointly improve their alpha mattes, which allows high
confidence local regions to guide their corresponding low confidence ones in other images to achieve more accurate
mattes all together. Experimental results show that this co-matting framework can achieve noticeably higher quality
results on an image stack than applying state-of-the-art single image matting techniques individually on each image.
|
Efficient View Manipulation for Cuboid-Structured Images
Yanwen Guo, Guiping Zhang, Zili Lan, and Wenping Wang
Computers & Graphics, 2014, 38: 174-182, (Proc. CAD/Graphics 2013). (SCI, EI)
We present in this paper an efficient algorithm for manipulating the viewpoints of cuboid-structured images with moderate user interaction. Such images are very popular, and we first recover an approximate geometric model with the prior knowledge of the latent cuboid. While this approximated cuboid structure does not provide an accurate scene reconstruction, we demonstrate that it is sufficient to re-render the images realistically under new viewpoints in a nearly geometrically accurate manner. The new image with high visual quality is generated by making the rest image region deform in accordance with the re-projected cuboid structure, via a triangular mesh deformation scheme. The energy function has been carefully designed to be a quadratic function so that it can be efficiently minimized via solving a sparse linear system. We verify the effectiveness of our technique through testing images with standard and non-standard cuboid structures, and demonstrate an application of upright adjustment of photographs and a user interface which enables the user to watch the scene under new viewpoints on a viewing sphere interactively.
|
| |
 Publications
Publications